
Human Pose Estimation vs. Facial Landmark Detection: Key Structural Differences Explained

In computer vision, understanding the human form is a powerful capability—one that unlocks everything from gesture-controlled interfaces to facial recognition systems. Two of the most widely used approaches in this space are human pose estimation and facial landmark detection. While both methods aim to locate key points on the human body, they differ in structure, scale, and purpose.
Human pose estimation focuses on identifying keypoints across the entire body, such as elbows, knees, or shoulders, to interpret physical posture or motion. Facial landmark models, by contrast, zero in on the face, pinpointing features like the corners of the eyes, mouth, and nose to capture expression, identity, or gaze direction.
Despite their similarities, these models are built and optimized in very different ways. In this blog post, we’ll break down the core structural differences between them—from the input size and architecture to the way they represent outputs—so you can better understand when and how to use each one.
Whether you're developing a fitness app that tracks body movements or a virtual makeup filter that responds to subtle facial cues, understanding the distinction between these two model types is key to building accurate and efficient computer vision solutions.
Overview of Human Pose Estimation Models
Human pose estimation is a branch of computer vision focused on identifying the precise positions of key joints in the human body from images or video. These models aim to map visual input—whether it's a single image or a continuous video stream—into a structured set of coordinates that represent the posture or movement of one or more individuals. From fitness apps to augmented reality and workplace safety, pose estimation serves as a critical foundation for many intelligent systems.
Key Objectives
The primary goal of pose estimation models is to locate and track anatomical keypoints such as shoulders, elbows, wrists, hips, knees, and ankles. Depending on the complexity of the application, some models may go further to estimate fingers, facial landmarks, or even subtle body orientations. Accuracy, speed, and robustness to occlusions (like when body parts are hidden) are central to the design and performance of these systems. In many real-world scenarios, especially involving video or real-time interaction, achieving a balance between computational efficiency and precision is crucial.
Common Architectures
Several model architectures have emerged as industry standards for pose estimation. OpenPose was one of the first frameworks to introduce multi-person pose estimation in real-time, using a part affinity field (PAF) approach to connect detected joints into full-body skeletons. HRNet (High-Resolution Network) took this further by maintaining high-resolution representations throughout the model, allowing for better localization of small or overlapping keypoints.
Other notable architectures include PoseResNet, AlphaPose, and BlazePose, each offering trade-offs in accuracy, speed, and implementation complexity. Some models prioritize speed for mobile or edge devices, while others are tuned for high-accuracy use cases in research or medical analysis.
Output Representation
Most pose estimation models output a set of 2D or 3D keypoints, each corresponding to a specific joint or body part. These keypoints are typically visualized as dots connected by lines to form a stick-figure skeleton overlay. The number of keypoints varies by model and dataset—some common standards include 17-keypoint and 21-keypoint formats, with coordinates often returned as part of a heatmap or through direct regression.
These skeletal representations provide a simplified yet informative abstraction of human posture, enabling downstream applications such as action recognition, gesture control, and motion tracking.
Overview of Human Pose Estimation Models
Human pose estimation is a field within computer vision that focuses on detecting and localizing key points on the human body from visual input such as images or video frames. These key points typically correspond to anatomical joints like shoulders, elbows, knees, and ankles. By analyzing the spatial configuration of these points, models can infer body posture, gestures, and motion—laying the groundwork for applications in fitness tracking, sports analytics, animation, and even human-computer interaction.
Key Objectives
At its core, the objective of a pose estimation model is to accurately identify the position of human joints and reconstruct a skeletal representation of the body. For this to be effective, models need to be robust to challenges like varied lighting, clothing, body sizes, and occlusion. Another important goal is to strike a balance between precision and processing speed—particularly for use cases requiring real-time performance, such as live video analysis or interactive environments.
Additionally, scalability plays a role. Some systems are designed for single-person detection, while others are capable of tracking multiple individuals simultaneously, even in crowded scenes.
Common Architectures
Over the years, a variety of model architectures have been developed to tackle the pose estimation task. Among the most well-known is OpenPose, which introduced an innovative two-branch system—one to detect key points and another to learn how those points connect. Its ability to detect multiple people in a single frame made it a breakthrough in real-time multi-person pose estimation.
Another widely used model is HRNet (High-Resolution Network). Unlike earlier architectures that downsample images and then try to recover spatial details, HRNet maintains high-resolution representations throughout the network. This design allows it to localize joints with impressive accuracy, especially in challenging scenarios with overlapping limbs or small-scale features.
Other noteworthy approaches include BlazePose by Google, optimized for mobile devices, and AlphaPose, known for combining high accuracy with good inference speed.
Output Representation
The final output of a pose estimation model is typically a set of 2D or 3D coordinates, each representing a specific joint. These coordinates are often visualized as dots, which are then connected by lines to form a skeletal "stick figure" overlaying the original image or video frame. This structure helps translate complex visual input into a simplified but meaningful format that software systems can interpret.
Depending on the dataset and model, the number of key points can vary—from a basic 13-point layout to more detailed formats with 17, 21, or even 33 points. Some models output heatmaps showing the likelihood of a joint being at a particular location, while others use direct coordinate regression for speed and simplicity.
This skeletal output becomes the foundation for a wide range of tasks, from posture correction to gesture recognition, enabling machines to understand and respond to human movement in intuitive ways.
Core Structural Differences
While human pose estimation and facial landmark detection both involve predicting keypoints on the human body, they differ significantly in how their models are structured. These differences stem from the unique challenges and precision demands of each task. From input size to model complexity, the structural choices made in each type of model reflect their specific use cases and data characteristics.
Input Preprocessing and Scale
One of the most noticeable differences starts at the input level. Human pose estimation models are generally designed to handle full-body images, often with multiple people at varying distances from the camera. As a result, preprocessing usually involves resizing images while maintaining aspect ratios and applying techniques like person detection or cropping around the full body.
In contrast, facial landmark models typically operate on tightly cropped face images. These inputs are much smaller in scale, but require greater precision. Subtle differences in facial expression or head orientation can impact performance, so preprocessing often includes facial alignment and normalization to ensure consistent orientation and scale.
Keypoint Density and Resolution
Another key distinction lies in the number and spacing of keypoints. Human pose models usually predict around 13 to 33 keypoints, spread across large areas of the image. These keypoints capture general body posture rather than fine detail. In contrast, facial landmark models often estimate 68 or more points, many of which are concentrated in small regions like the eyes, mouth, and jawline. This high-density mapping requires finer resolution and a more localized focus within the network.
Network Depth and Feature Granularity
To support their different levels of detail, the internal architectures of these models also vary. Human pose estimation models often rely on deeper networks or multi-stage designs that gradually refine predictions at different scales. These models must capture broad contextual information—like body orientation or inter-limb angles—before zeroing in on individual joints.
Facial landmark models, however, are more focused on extracting fine-grained features from small image patches. They tend to emphasize high-resolution feature maps earlier in the pipeline, enabling the detection of minute variations in skin texture, contour, and shadow—factors critical for accurate facial mapping.
Use of Heatmaps vs. Regression
Both types of models can use either heatmaps or coordinate regression to predict keypoints, but their preferences often differ. Human pose models frequently use heatmap-based approaches, where each keypoint is represented as a probability distribution over a spatial grid. This method works well for large-scale detection and provides a visual understanding of where joints are most likely to appear.
Facial landmark models, especially lightweight ones for mobile or embedded devices, often favor direct regression—outputting (x, y) coordinates without generating full heatmaps. This allows for faster inference and is sufficient for the relatively small area of the face, though some high-accuracy models still incorporate heatmaps for better spatial precision.
Model Complexity and Speed Considerations
Because they deal with full bodies, sometimes multiple people, and more complex spatial relationships, human pose estimation models tend to be heavier in terms of computational load. They often require more memory and processing time, particularly when designed for high-accuracy applications like video analysis or biomechanics.
Facial landmark models, by contrast, are usually more lightweight and optimized for speed. Many are designed to run in real time on mobile devices or in-browser applications. Their lower input size and narrower focus make it easier to design fast, responsive models without sacrificing much in terms of accuracy.
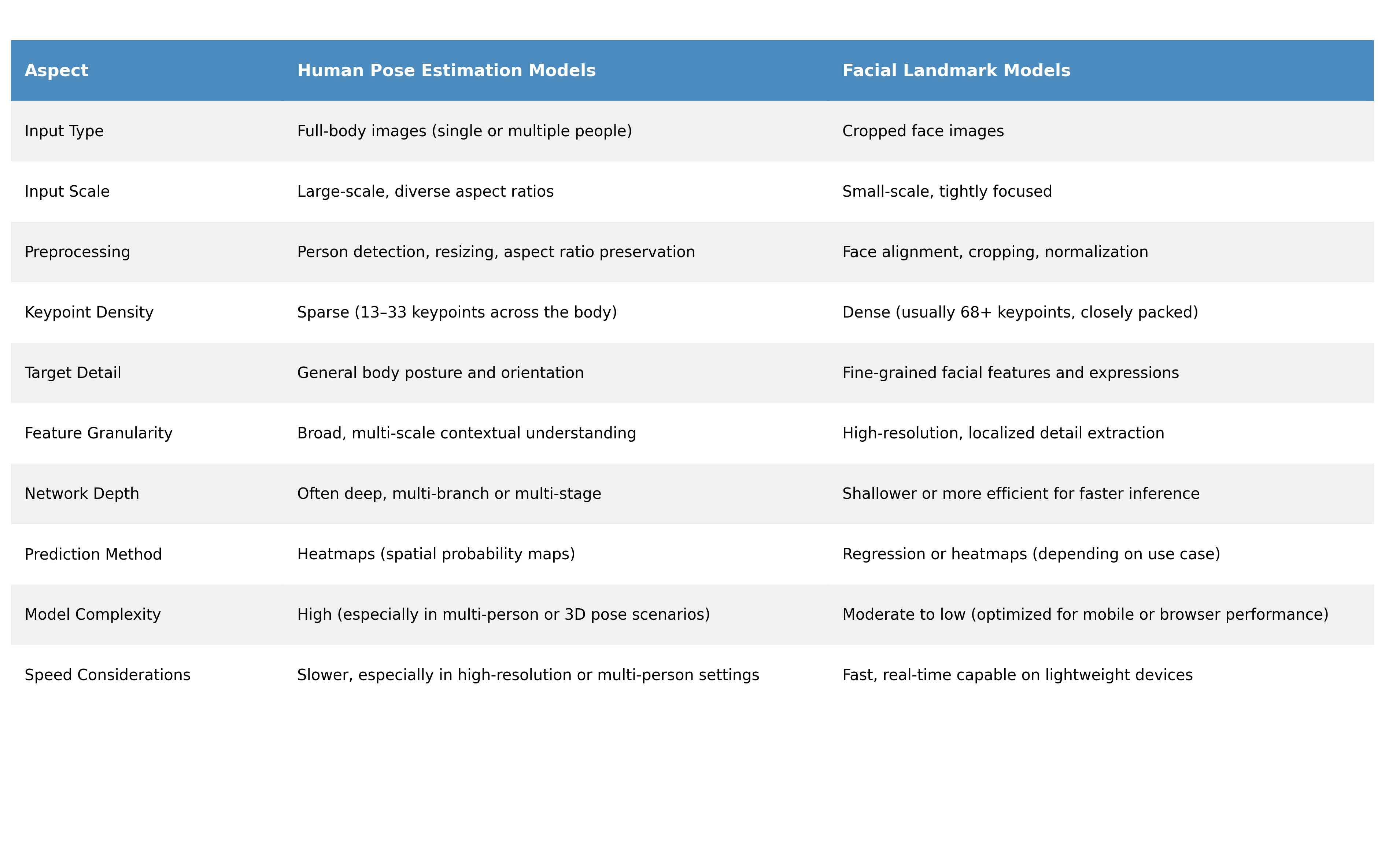
Summary Table: Structural Differences at a Glance
Conclusion
Understanding the structural differences between human pose estimation and facial landmark models is essential when building computer vision systems that involve interpreting the human body or face. While both model types share the core task of keypoint detection, they differ significantly in terms of scale, granularity, network architecture, and performance priorities. These distinctions are not just technical—they directly influence how and where each model is best applied.
Use human pose estimation models when your application involves full-body movement, gesture recognition, or multi-person interaction. These models are ideal for scenarios like sports analytics, motion capture, fitness apps, surveillance, and augmented reality systems that need to understand body posture or track people across frames. Their ability to detect joint positions and body orientation makes them powerful tools for interpreting physical actions in space.
Facial landmark models, on the other hand, shine in tasks that require detailed understanding of facial features. If your goal is to analyze expressions, enable face-based authentication, drive face filters, or perform fine-grained emotion recognition, facial landmark detection is the better choice. These models are lightweight, fast, and capable of high-precision tracking of subtle facial movements—making them particularly useful for mobile apps, virtual try-ons, and in-browser experiences.
In summary, choosing the right model type depends on what part of the human form you need to understand—and how detailed or responsive that understanding must be. By matching the model to the task, you can unlock both performance and efficiency in your computer vision pipeline.
